
Preface
Planning project releases and iterations with story points, rather than hours, comes from Agile Software Development. The Agile Software Development manifesto suggests that we value customer collaboration over contract negotiation. The trouble with using hours to plan happens when we present an estimate of 40 hours to a process owner. We set an expectation, or contract, that the functionality is delivered in the course of a week. Story points, however, give us a more arbitrary means to measure scope for planning a release or iteration with relative sizing of the user stories. This situation allows us to collaborate on a plan without confusing hourly estimates as schedule contracts with far more accuracy and precision than we have.
When we start managing project implementation with a detailed estimate, we use user stories and story points to size delivery components. Our detailed estimate should be revised at the end of every development iteration. As the project progresses, and the cone of uncertainty narrows, we can apply a narrower ranges of uncertainty. Using the earlier described PERT approach, we might restrict our revised estimate from PERT+2 to PERT+1, and ultimately move to PERT+0 in later iterations.
As we drill down in the granularity of what we are estimating, we have more detailed knowledge of solution artifacts and scope. Our estimates improve in both accuracy and precision. We use different measures at different levels of granularity.
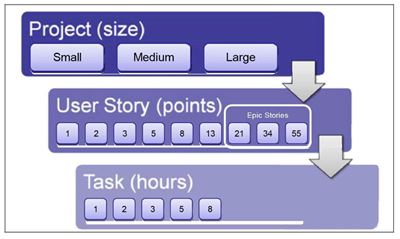
Measuring scope with user story points
A BPM project/program manager collaborates with the development team when estimating user stories. If this estimating activity is performed by the lead developer alone, then the accuracy of the estimate is highly dependent on that individual's experience and whether they are generally optimistic or pessimistic. It is better to involve either the entire delivery team or a good cross section of the team. This situation allows developers to challenge each other and raise questions that others might not consider. User story point estimates based on general consensus are more accurate.
As the development team reaches consensus, they think about the various solution components the user story requires. Design considerations and questions are documented as notes or comments on the user story to provide justification for the estimate and provide useful information to developers during implementation.
Teams use story points differently, but the two most popular ways to measure using story points are either on a scale of 1 (low effort) to 10 (high effort) or a Fibonacci sequence (0, 1, 2, 3, 5, 8, 13, 21, 34, 55). The Fibonacci sequence is useful in that it reflects the manner in which uncertainty (vagueness) plays a part as the story gets bigger and more complicated. Both methods have pros and cons; what is important is that you chose a method that works for you and your team knowing that you can modify later if it is not working.
Breaking down epic user stories
User stories that cannot be implemented in a single iteration should be further broken down into smaller user stories, or substories. An example could be stories that have data integration dependencies or complex navigation. Some of these large stories have multiple facets that are specific to a complex feature; these stories are often referred to as epic user stories. Epic user stories are too large and contain too much ambiguity to estimate accurately. If using the Fibonacci sequence method of estimating story points, any story larger than 21 story points might be an epic. Over time, your teams recognize epic stories. Epic stories do not need to be broken down immediately upon discovering them. They need to be broken down only when loading an iteration and scheduling user stories for implementation.
Teaming with user story points
The concepts a team uses to estimate a user story in story points (effort, complexity, and uncertainty) are subjective measures. The story points estimated by one team differ from the estimate by another team for the same user story. This situation is perfectly normal and should be expected. Each team of developers bring their own experiences and unique perspectives on what is complex. Team variations in prior knowledge and experience account for different estimates. If we assign user stories to a different team, the point estimates for the user stories should be revisited by the new team.
Measuring team velocity with user story points
User story points are relative in the sense that two user stories that have the same story point value should be relatively the same size. This situation does not mean that two stories of the same point value should consume the same amount of development hours. We can have two user stories of the same estimate, but one could be complicated and have low effort while the other could be high effort but have low complexity.
The user story points help us measure scope so that we can plan releases and iterations. After completing several iterations with the same team, we have a good measure of the team's velocity in story points. This measure is key to planning the scope achievable in future iterations and releases.
Hours worked in a day: Do not assume developers complete 8 hours of development tasks each day. These estimates are for actual development effort and do not include time spent presenting mini-playbacks to process owners, collaborating with SMEs, building prototypes, attending meetings, creating documentation, and so on. Research suggests that experienced developers perform an average of 6.5 hours of development work each day. Developers with less experience, user stories with more ambiguity, and tasks involving high complexity further reduce the hours of work completed in a day.
Writing user stories with Blueworks Live
During the discovery phase, the BPM analyst helps SMEs write their own user stories. Each activity in the business process contains at least one user story, but more likely has five or more user stories. User stories are a simple reminder that should prompt additional discussion and collaboration between the user story owner (SME) and the BPM developers during process implementation. Although Blueworks Live is not an agile project management tool, it is the first place we might capture user stories during process discovery, documentation, and analysis.
Before agile software development, traditional requirements were documented by analysts as functional specifications, or as a software requirement specification (SRS). The SRS included a logical breakdown of the component parts of the solution and use cases. User stories differ from traditional specification documentation, as they focus purely on the business requirement and do not take solution design consideration into account. Each user story should be no more than 2 - 5 sentences and should follow this format:
The most important part of the user story is the so that part that illustrates the business value in the user story. This business value helps all members of the team stay focused on delivering that business value, and less concerned with the systems, technology, design patterns, and solution detail we might use to implement the user story. The business value is also important in prioritizing user stories for project planning.
Finding the user story in activity documentation
A business process definition might contain several levels of subprocess before reaching activities that are performed by a human or system. The activity description should describe the steps that are performed by the participant. For example, the Take Screening Test activity has the following activity description:
The candidate completes a 30-minute test so that the HR Manager can assess the candidate's proficiency in languages (English, Spanish, and Chinese). The candidate also completes a 5-minute typing test, so the HR Manager can rate the speed and accuracy of their typing skills.
Sometimes a user story cannot be implemented in its entirety in a single iteration when all of these layers are considered. Furthermore, dependency on integration development outside the process application can block completion of the integration components. In these cases, a user story can be subdivided into multiple substories to implement and delivery Process, Activity, Coach, and Integration level components independently.
Avoid writing passive user stories
These user stories might seem reasonable. However, these stories are examples of passive user stories. The main participant (candidate) is less significant than the beneficiary (HR manager). It is better to write active user stories where the main participant is the individual that is performing the activity. This situation is how users are expected to interact with the BPM solution. When requirements are expressed as active user stories, you might discovery additional user stories, as shown in the following shaded box.
Throughout discovery and implementation, we continue to identify missing or new user stories and add them to the backlog. User stories provide a set of requirement reminders for the BPM solution.
Taking these user stories into consideration, the user stories shown in the following shaded box were captured for the Take Screening Test activity in our example.
Managing the user story backlog
The project backlog is the queue or container for all user stories not yet completed or scheduled for an iteration. At the start of the project, all user stories are entered into the backlog. As we plan new iterations, we pull user stories out of the backlog. As new user stories are created during the project, we add them to the backlog. At the start of each new iteration, the process owner can prioritize brand new user stories alongside previously written user stories. In this method, the process owner has control over the scope of the project. It is typical that the backlog increases in size during the first release of the project. This situation means that the team, including the process owner, SMEs, and developers, all help manage scope by creating user stories (or reminders) of additional capability identified during the project. The project should end with user stories in the backlog ready for planning another release.
Prioritizing user stories
The process owner and SMEs are responsible for prioritizing user stories. This priority helps the process owner work with BPM developers during iteration planning to identify which stories to add to the iteration and work on first. When prioritizing the backlog, it helps to simplify the view and arrange stories into three groups: high, medium, and low. Give each user story a priority indicating the business value the user story represents in correlation with corporate and project objectives.
Priority Assessment Description High Must have I cannot do my job without this item. Medium Have a workaround It is painful, but I can do my job without this item through a workaround if I know that it is temporary. Low Nice to have,
or Not required
This feature would make my job a lot easier, but it is not in the critical path.
This feature is not necessary or pertinent for me to do my job.
Planning, committing, and accepting iterations with user story points
The process owner collaborates with the development team to plan iteration themes and load iterations with user stories. We use story points to measure scope so that we can schedule resources that align with the duration of the iteration. After loading an iteration with user stories, BPM developers review the user stories and define work items (development tasks) for each user story. This activity is collaborative, as developers rely on the user story owners to answer questions, provide examples, and elaborate on the details needed to start implementation.
After all user stories have development tasks estimated in hours, the team collaborates again to verify that the estimated hours fit in to the scheduled duration of the iteration and resource plan. If the iteration is overloaded, process owners remove user stories based on priority until the iteration fits the resource schedule. At this time, the process owner and development team commit the iteration. Upon completion of all development tasks for a user story anytime before the iteration ends, the process owner accepts the user story as completed. After all the user stories are accepted, the iteration is accepted.
Estimating development tasks with hours
The developers (and only developers) are responsible for estimating the hours needed to complete each development task. A best practice is that no development task should be more than 8 hours. Some teams prefer to use a Fibonacci sequence (0, 1, 2, 3, 5, 8) for tasks. Tasks larger than 8 hours should be further broken down into multiple tasks, or subtasks. Tasks larger than 8 hours leave too much room for uncertainty due to ambiguity or variability due to unplanned events or risks.
Another best practice is for developers to update the estimated hours remaining on their tasks daily. If the work remaining increases due to new knowledge or unforeseen events, the risk is immediately visible in the iteration burn-down chart and the team can react accordingly.
Managing development tasks in iterations
Iterations, also referred to as sprints, are the time-boxed containers for managing development. Iterations are important in establishing project cadence, setting delivery expectations with the process owner, and measuring the progress of work completed.
If new information about development work surfaces during the iteration, or assumptions change, user stories can be removed from the committed iteration. However, no new user stories should ever be added to the iteration after the iteration is committed and started. This situation does not mean that developers cannot start work on other user stories. It does means that a committed iteration is an agreement between developers and process owner and it is unfair to add scope to an iteration after it is committed and started.
Monitoring iteration burn-down
After an iteration starts, we monitor burn-down of effort remaining in hours and burn-up in user story points accepted. This situation means that the team takes hours and reset estimates for effort remaining as development tasks are updated daily. This situation also means the user story points accepted should trend upward as user stories are accepted by the process owner.
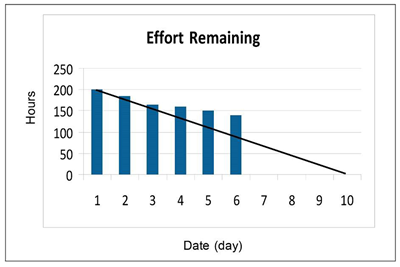
The goal is to accept all user stories before the end of the iteration. This goal is not always possible and sometimes a user story either requires more work than originally estimated, or the user story is not accepted by the process owner. If the story requires more development effort before it can be accepted, we can remove the user story from the iteration and schedule it in the next iteration. The team gets no credit for user story points in the current iteration, as no working software is accepted by the process owner.
In our example scenario, we plan two-week iterations (10 workdays) for a team of three developers at various levels of experience. As there are not quite eight full hours in a workday, we plan iterations with no more than 200 hours of development tasks (three developers x 10 days x 6.5 hours per day). The example iteration burn-down chart in Figures: 2.2.4/1-3, 2.3.3/1-2, 2.4.1/1, 2.4.2/1, 2.4.3/1, 2.4.6/1-3 shows an iteration in trouble. The work remaining is not trending downward at a rate that completes all the work by the end of the iteration.
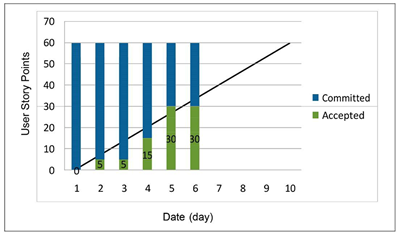
Do not correlate story points with hours
It is common for teams new to agile software development to try to correlate story points with hours. Resist this temptation! Creating a correlation between points and hours (for example, 5 hours per point) invalidates the benefits of planning in points. It also assumes homogeneous experience and expertise.
If you want to associate time with points, then the time should be done as ranges for each point. You should use a model that incorporates uncertainty, such as a Fibonacci sequence (for example, five points would relate to a range of 32 - 48 hours). The range should be tighter for smaller points (for example, 6 - 10 hours for a single point estimated story) and greater for larger point estimates (for example, 40 - 80 hours for an eight-point estimated story).
Using team velocity instead
Our desire to correlate story points with hours is based on our motivation to forecast and plan. We ask ourselves, “How long does it take to implement 100 story points?” We can answer this question with team velocity. Team velocity is measured in story points accepted per iteration and should be based on historic team performance to include the most recent 4 - 6 iterations (teams improve velocity over time). We can apply a range to our estimates to include optimistic, most likely, and pessimistic values when planning releases or iterations. If we do not have historic team performance data, we use an initial estimated team velocity to plan a series of iterations based on various sized teams. After the team delivers several iterations, we use actual team velocity and further refine the project schedule.