
5.3. Retrievability of data
Clients relying on a remote data storage can potentially move very large amount of data to the cloud. The data should be faithfully stored and the cloud providers should make them available to the owner (and perhaps others) on demand. The storage servers however are assumed to be untrusted in terms of both security and reliability. They may maliciously or accidentally erase or change a part of hosted data. They might also relegate the data to slow or off-line storage. Thus, the storage outsourcing carries the potential risk of loosing the data and the data owners are interested in verifying that the cloud providers are not cheating. Even if clients are not (immediately) interested in the data retrieval, they are concerned about the durability and consistency of hosted data.
Minimum condition
As a minimum condition a data owner should be able to efficiently, frequently and securely verify that:
- His data is still available in the cloud in its original form (the servers are reliable and do not lose or inadvertently corrupt hosted data).
- The data has been corrupted by the cloud servers (if the servers are malicious).
Fig. 5.3/1: Scenario
We may see few challenges in the matter of data retrievability. Namely:
- Typically, the owner does not keep a copy of data stored in the cloud. So there is no reference to data on the owner's side that can be used for a comparison.
- Volume of data exchanged between the user and the cloud should be minimized. In particular, downloading the data from the cloud and integrity checking can be done occasionally, but as a system routine it is practically infeasible.
- Sometimes the client might be a small device (e.g. a cell-phone) with limited resources - not only communication facilities but also CPU and battery power. Hence, we may need to minimize the local computation overhead for the client in performing each verification.
Retrievability of data -- naive solution
- Generate a signature \(s\) of a payload data \(D\).
- Store \(D\) together with \(s\).
- In order to check the integrity, download \(D\) and \(s\) and check the validity of \(s\).
Downloading the whole data \(D\) for every check is very costly!
The methodology for solving the problem of availability of data stored on untrusted servers appeared in the literature under the slogan:
- PDP - Provable Data Possession
- POR - Proof of Retrievability
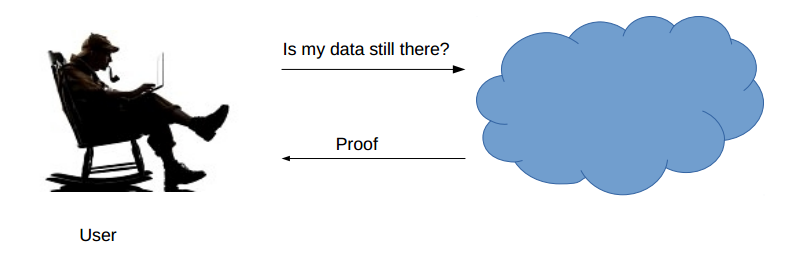
Fig. 5.3/2: PDP/POR Scenario
What is PDP/POR?
PDP/POR is a typically challenge-response protocol which, without retrieving the data by the client, gives the client a cryptographic proof that the server possesses his data in the unchanged form.
Terms PDP and POR are often used interchangeably. We can find however a variety of different approaches to the topic and different properties of resulting schemes. Some of them (like : 1 or : 5 ) are based on public-key-based techniques and thus allow to achieve public verifiability (any verifier, not just the client, can query the server and obtain an interactive proof of data possession). Another (like : 4 ) are dedicated to encrypted data and are based on hiding special blocks in the data (called sentinels) that can be used to detect file modifications. However, only a fixed number of challenges is allowed and verification can be done only by the data owner.
General approach to proofs of possession
Generally a PDP scheme in this approach consists of the following procedures:
- Preprocessing phase: a client creates a meta-data \(M_D\) for a given file \(D\) (small volume, kept locally by the client) and (optionally) some tags \(T_D\) for a given file \(D\).
- Transferring phase: a client transfers data \(D\) to a remote server together with tags \(T_D\).
- Checking that \(D\) is stored by the server:
- Challenge phase: a client presents randomized challenge \(c\) (based on \(M_D\)).
- Response phase: a server using \(D\) and \(T_D\) and the challenge \(c\) computes a proof \(P\) of possession data of \(D\).
- Verification phase: a client verifies the proof \(P\) using meta-data \(M_D\) and the challenge \(c\).
Perhaps the simplest solution for PDP is based on a cryptographic hash function \(H\). The protocol goes as follows:
- A client chooses at random keys \(k_1, \ldots, k_n\) and computes corresponding proofs \(p_1, \ldots, p_n\), where \(p_i = H_{k_i}(D)\) and \(H\) is a keyed hash function. After this precomputation data \(D\) are stored at the server.
- During the ith challenge phase the clients sends \(k_i\) to the server. The server computes \(p'_i = H_{k_i}(D)\) and sends \(p'_i\) back to the client. If \(p'_i = p_i\) , then the client can assume that the server holds the original file \(D\).
Advantages
- simple construction
Disadvantages
- server has to read the entire file \(D\) each time while computing the proof
- client has to keep all the proofs \(p_1, \ldots, p_n\) to enable the verification
- client can check the server only \(n\) times, where \(n\) must be fixed during the preprocessing phase
Deswarte et al. (see : 2 ) and Filho et al. (see : 3 ) provided techniques to verify that a remote server stores a file using RSA-based hash functions. According to this kind of schemes:
- A client during the precomputation phase computes hash: \(h(D):= D\; \mbox{mod}\; \phi(N)\), where \(N\) is a RSA modulus (\(N= pq\), \(p,q\) are primes, \(\phi(N) = (p-1)(q-1)\)).
- Then the client stores \(D\) together with \(N\) at the server.
- When the client wish to check if the server still has his data \(D\), he sends to the server a random challenge \(b \in \{1, \ldots, N-1\}\).
- Server computes \(r:= b^D \;\mbox{mod}\; N\) and sends it back.
- Finally the client computes \(r' := b^{h(D)} \;\mbox{mod}\; N\) and checks if \(r' = r\).
Advantages
- a client can perform multiple challenges using the same meta-data \(h(D)\)
- low communication bandwidth and the client storage bandwidth
Disadvantages
- server has to read the entire data \(D\) each time while computing the proof
- high computational complexity at the server side (exponentiations of the entire data)
(from : 5 )
A file \(D\) to be stored in the cloud is divided into blocks and each \(i\)th block into \(z\) subblocks, say:
\[
m_i=m_{i,1}\ldots m_{i,z}, \qquad m_{i,1}\ldots m_{i,z}\in Z_p
\]
The \(i\)th block also corresponds to a secret polynomial \(L_i\) of degree \(z\) known to the data owner
but unknown for the cloud.
We assume that the subblocks are pairwise different, e.g. each subblock
contains its serial number. Additional parameters (used during polynomials generation):
- \(SK\) -- master secret key of the user,
- \(ID_f\)
For each subblock \(m_{i_j}\) the client computes a tag \(t_{i,j} := L_i(m_{i,j})\). All the data together with tags are stored at the cloud. During a challenge phase for a single block \(m_i\) a client:
- chooses \(r, x_c\) at random (\(x_c \neq 0\) and different from all the subblocks of \(m_i\))
- computes \(K_i:=g^{rL_i(x_c)}\) and stores it locally
- computes \(g^r\) and \(g^{rL_i(0)}\) and sends them to the cloud together with \(x_c\)
- computes \((g^r)^{t_{i,1}}, \ldots, (g^r)^{t_{i,z}}\)
(they are equal to \(g^{rL_i(m_{i,1})}, \ldots, g^{rL_i(m_{i,z})}\) ) - uses Lagrangian Interpolation in the exponent (see Lagrangian in Additional materials) to compute \(g^{rL_i(x_c)}\)
(\(m_{i,1}, \ldots, m_{i,z}\) must be used) - returns \(g^{rL_i(x_c)}\)
Advantages
- a client can perform multiple challenges
- construction, that utilize standard cryptographic operations
- the scheme can be easily transformed to achieve public verifiability
- the possibility of getting the proof only for some number of blocks or for all of them
- low communication bandwidth - in case of checking many blocks the challenge and proof of possession can be easily aggregated -- the trick is to use different polynomials for different blocks but with the same value at 0. Then the short challenge is \(x_c, g^r, g^{rL(0)}\)
- the client storage usage can be really low - the data owner does not have to store all polynomials (one polynomial per block). They can be generated in a pseudorandom way from some secret seed chosen by the data owner.
Disadvantages
- many exponentiations (especially while creating the proof by the server side)
Given
- \(L:Z_q\rightarrow Z_q\) polynomial of degree \(z\)
- \(A'=\langle (x_0,g^{rL(x_0)}), \ldots , (x_z,g^{rL(x_z)})\rangle\),
where \(x_1, \ldots, x_z\) are all different
Lagrangian Interpolation in the exponent
\[ \begin{eqnarray*} LI_{EXP}(x,A')& \stackrel{\textrm{def}}{=} &\prod^{z}_{i=0,(x_i,.)\in A'} { {\left( g^{rL(x_{i})}\right)}^{ \prod^{z}_{j=0, j\neq i}{\left( \frac{x-x_j}{x_i-x_j}\right)} } }. \end{eqnarray*} \]
Note that \[ LI_{EXP}(x,A') = g^{ r\sum^{z}_{i=0,(x_i,.)\in A'} { \left({ {L(x_{i})} } { \prod^{z}_{j=0, j\neq i} { \left( \frac{x-x_j}{x_i-x_j} \right) } }\right) } }= g^{rL(x)} ~. \]
Ateniese, G., Burns, R.C., Curtmola, R., Herring, J., Kissner, L., Peterson, Z.N.J., Song, D.X.: Provable data possession at untrusted stores.
Deswarte, Y., Quisquater, J., Sadane, A.: Remote integrity checking - how to trust fi les stored on untrusted servers.
In Jajodia, S., Strous, L., eds.: Integrity and Internal Control in Information Systems VI - IFIP TC11/WG11.5 Sixth Working Conference on Integrity and Internal Control in Information Systems (IICIS) 13-14 November 2003, Lausanne, Switzerland. Volume 140 of IFIP., Springer (2003) 1- 11. http://dx.doi.org/10.1007/1-4020-7901-X_1
Filho, D.L.G., Barreto, P.S.L.M.: Demonstrating data possession and uncheatable data transfer.
IACR Cryptology ePrint Archive 2006 (2006) 150. http://eprint.iacr.org/2006/150
Juels, A., Jr., B.S.K.: Pors: proofs of retrievability for large fi les.
Krzywiecki, Ł., Kutyłowski, M.: Proof of possession for cloud storage via lagrangian interpolation techniques.
In Xu, L., Bertino, E., Mu, Y., eds.: Network and System Security - 6th International Conference, NSS 2012, Wuyishan, Fujian, China, November 21-23, 2012. Proceedings. Volume 7645 of Lecture Notes in Computer Science., Springer (2012) 305-319. http://dx.doi.org/10.1007/978-3-642-34601-9_23